OCR comparison: Tesseract versus EasyOCR vs PaddleOCR vs MMOCR
You probably know there are lots of open and freely usable Optical Character Recognition engines out there. But to know how they perform in relation to each other is not easy to track or test out. I have seen claims like:
- Go with Tesseract on CPU but if you have GPU available, use EasyOCR
- Tesseract excels on individual characters while EasyOCR works best on complete words.
Is that true? I’ll show you a tool to help you find out.
I’ve stumbled on this 🤗 (huggingface) space made by Laurence Dewaele.
It allows you compare the results of the text recognition between these four OCR methods:
Tesseract OCR
Tesseract OCR is a free, open-source optical character recognition engine developed by Hewlett-Packard and later maintained by Google, releasing a major update in 2014 (Tesseract 3.0) and another in 2018 (Tesseract 4.0).
EasyOCR
EasyOCR was developed by Jaided AI, a team of software engineers who specialize in developing computer vision and machine learning applications. The first version of EasyOCR was released in August 2019, and since then, it has gained popularity among developers, researchers, and students who work with OCR technologies.
MMocr
MMOCR (Multimodal Optical Character Recognition) is an open-source OCR (Optical Character Recognition) project developed by OpenMMLab. It was first released in 2020 and has since gained popularity due to its high accuracy in recognizing text from images and videos.
PaddleOCR (PPOCR)
Multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
I uploaded a test image from the FUNSD dataset. The process is done in two stages. First every OCR solution will do a text detection of the page. This will return boundingboxes with the location of words/segments it discovered. Although all of them support a multitude of languages, I'm just testing here on English. I leave the hyperparameters to default, in the (vain) hope that the developers already found the best settings for most common scenarios.

You’re then presented with the results of the text detection. Can you spot the differences?
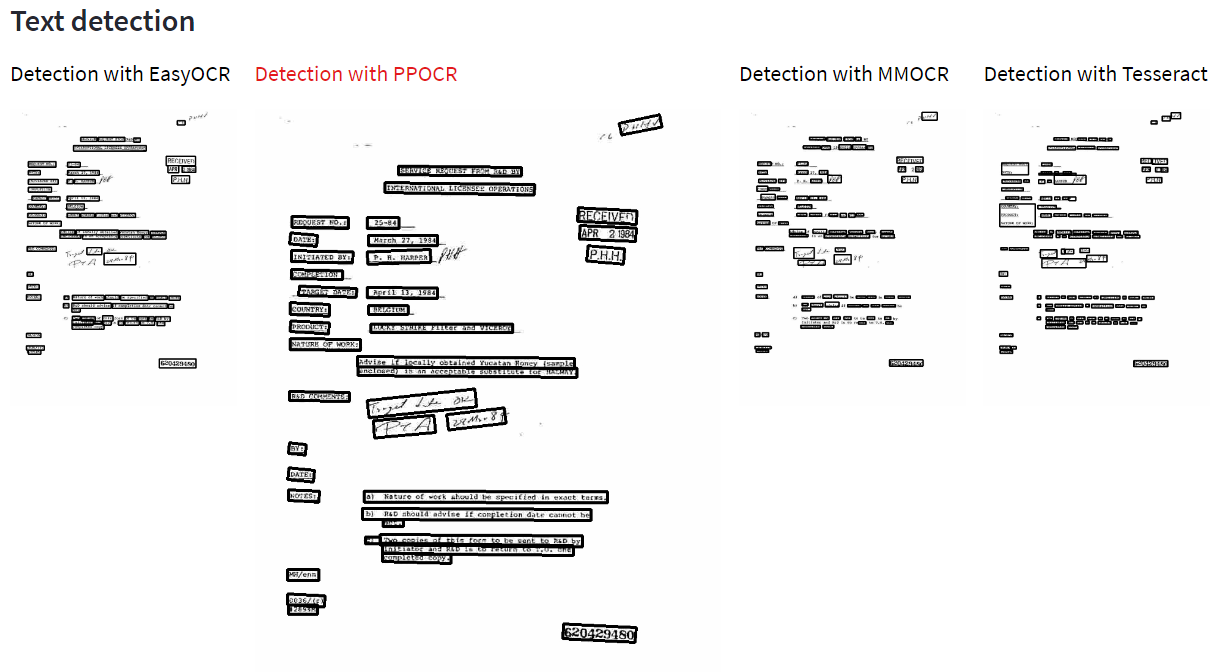
Let’s have a look in detail:




Observations:
Tesseract seems to miss text and breaks some words that belong together in seperate boxes. In a lesser extent the same is valid for MMOCR. I think both EasyOCR and PPOCR are on par here, but I like the fact that PPOCR is the only one that has slanted (not straight) boxes.
Why is text detection important? Because the OCR solutions don’t do recognition on the complete page, but rather these boxes where it discovered text inside. Layout awareness is a big help to get more accurate OCR results. The next step is to choose which one of the four text detections we will use to feed those results to the actual recognition step. I chose Paddle OCR, again with default parameters for each OCR implementation.
Here are some results:
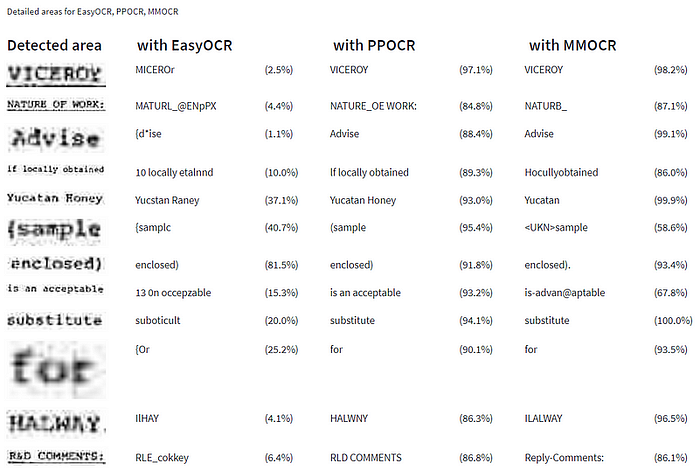
PPOCR seems to win in this case. Lines under words can be very hard for OCR. In the last example, MMOCr seems to make up words, in casu ‘Reply’ instead of ‘R&D’. Maybe it uses a dictionary by default.
Tesseract OCR needs to use its own detection, so the results are not completely comparable one on one unfortunately. The results below are surprisingly bad.

Conclusion
It’s hard to compare the OCR solutions, because they are in constant development and there are many more than the four I talk about here. The above document I tried out is just one sample and with default parameters. So take these results with a grain of salt. (or a bucket of salt) I must mention it also depends on the OCR application. One solution could be better for documents while the other is better for reading things like license plates. The 🤗 space by Laurence Dewaele certainly helps a little in this effort. Try it out!
(if you want to read more articles like this, be sure to follow me here on Medium)
References
